College Board, the company that designs and administers the Scholastic Achievement Test (“the SAT”, the most popular standardized test used in admissions to colleges and universities in the United States), recently announced that it would be releasing a revised form of the SAT in Spring 2016. Among the changes is a revised vocabulary section, which promises to avoid the obscure vocabulary that the test is infamous for.
These changes are likely driven in part by critics’ contentions that rather than simply measuring any type of objective aptitude or preparation for undertaking academic work, the results reflect test-takers’ socioeconomic status (for example, here, here, and here).
So why is the vocabulary section a prime target for change? Well before I can address this, we need to consider what it means for a test to be a good test. Researchers (in testing and other fields) talk about the validity of tests and research instruments. Broadly speaking, this has to do with whether or not the test measures what we want it to, and also when we’re talking about a test like the SAT that has such broad societal impact, that the test serves the function that we want it to. In this case, I think it’s pretty noncontroversial that in order to be a good test the SAT should provide a fair means to determine whether test-takers have the skills and competencies necessary for academic work at a college or university. Ultimately, we’d like to see it provide a way of evaluating students on their merits and not their privilege, although it’s probably too much to expect that any test can fully deliver this given the inequalities in education in the United States that will inevitably be reflected at least to some extent in test-takers’ results (hence, improving the SAT can really only do so much in terms of addressing inequalities).
In principle, vocabulary is something that might have relevance for determining whether a student is likely to succeed at academic work. Consider that much of being a college student is about reading and writing and even often learning about new concepts and being tested in a way that overtly focuses on “new words” (such as tests where students are asked to write definitions for new concepts).
Vocabulary researchers often discuss the idea that one needs to be able to recognize and understand a certain threshold of words in order to comprehend a text. For example, Norbert Schmitt, Xiangying Jiang, and William Grabe suggest that knowing 98% of the words in a text is a reasonable target to ensure comprehension for second language learners. Hence, if we need to know a certain number of words in a text in order to comprehend it (note that we can acquire new words, use a dictionary, or guess meanings from contexts for whatever remainder of the text is left), then obviously a larger vocabulary size will allow us to read a greater number of texts. However, not every word is equally useful, and this is one of the fundamental flaws in the SAT’s vocabulary testing as it currently operates.
Take, for example, this list of 100 vocabulary words, touted by Kaplan (a test preparation company) as the most important SAT words. While all of these words may be useful in terms of increasing your score on the SAT, they are not all equally useful in terms of doing the type of work that one will encounter as a student at a college or university: reading academic texts, writing papers, and listening to lectures or participating in discussions. The extent to which this is true is illustrated by the graph below (or you can click here for an enlarged version). It shows the frequencies (per 1 million words) of each of these 100 words in three different corpora stacked on top of each other:
- Reading: The Corpus of Contemporary American English‘s Academic subsection — consists mainly of publications in academic journals
- Writing: The Michigan Corpus of Upper-Level Student Papers — consists of advanced undergraduate and graduate students’ writing that received an “A” at the University of Michigan
- Speech: The Michigan Corpus of Academic Spoken English — consists of various speech events (especially classroom language) recorded at the University of Michigan
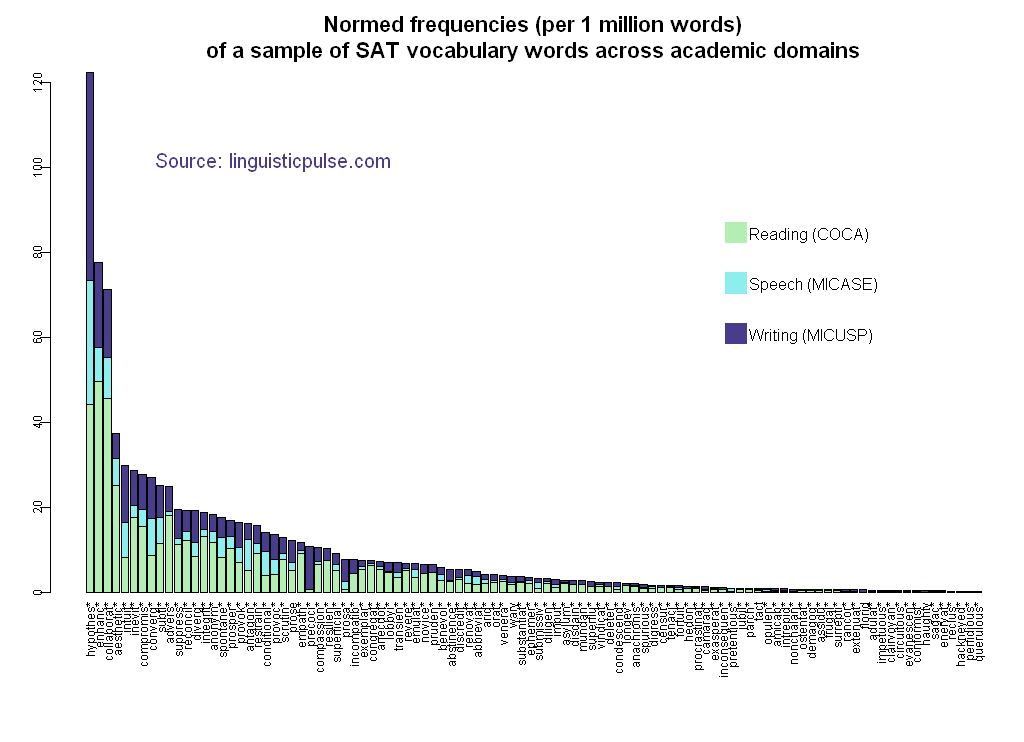
Notice the extremely tall bar all the way on the left. This represents the word family for hypothesis (word families include morphologically related words like hypotheses and hypothesize; this is done to reflect the fact that usually knowledge of a particular form of a word implies knowledge of other forms). In this data, hypothesis and its related forms show up about 123 times per million words. You can think of that number in the following way. If a student reads a 5000 word article for class, there’s about a 60% chance that the word hypothesis (or a related form) will appear in the text. In addition, an hour lecture will likely have around 7000 words in it. The likelihood that hypothesis (or another member of its word family) will show up is also around 60%. Finally, if a student writes a five-page paper (about 2500 words), there’s about a 37% chance they’ll include a member of the hypothesis word family in their writing. Of course, the probability is greater or smaller depending on disciplines, with students in science classes being quite likely to use hypothesis at least once and the those in the humanities far less likely to use this particular word.
We can compare this to the other end of the spectrum where we find words like querulous, perfidious, hackneyed, reclusive, and enervating. On average, none of these words even occurs once per million words in academic language. To conceptualize that, we could expect to find each of these words once in every 400 five page student papers, once in every 140 hour-long lectures, or once in every 200 5000-word articles. Again, other factors especially disciplinary variation do apply; for example, as a literature student I remember reading the word hackneyed quite frequently.
Beyond simply thinking about the frequency of these words, however, we might also consider their function. On the one end, we have hypothesis, which refers to a highly specific aspect of a central academic practice: undertaking scientific inquiry. In this case, knowing the word may indicate knowledge of something broader: knowing a concept, an entire set of important practices or at least familiarity with the language used to undertake those practices. On the other end though, what does knowledge of the word hackneyed indicate? Unlike hypothesis, hackneyed does not have a clear relationship to central academic practices. It may be occasionally used to express an opinion about what one perceives as clichéd, but the concept it describes is not one that any person likely lacks a term to describe. The vocabulary that college and university students will likely acquire during their academic experience (and perhaps may even often be tested on) are things like lepton, plastid, structuration, ethnography, or Bildungsroman (which do not appear on the SAT because it is not intended to measure disciplinary knowledge). There is therefore potentially a connection between new vocabulary and new concepts, but we shouldn’t simply assume that every new word represents additional knowledge or a new concept.
My point then is that the likelihood that a student will need to interpret or use most of the SAT’s vocabulary, let alone have their academic success impacted in some noticeable way by their recognition of it, is remote. That means that by testing, to a large extent, words like querulous, which are extremely infrequent and have no clear connection to academic practices, the SAT fails an important test of validity: designing the test so that it closely resembles the task that we wish to predict the test-takers’ potential success on. If the SAT’s vocabulary section is supposed to in any way provide a test of how students cope with the language of academic writing, reading, or speaking, it fails in its current form.
Yet many defenders of the SAT have noted that the test has what they call ‘predictive validity’, which simply refers to the fact that the test tends to correlate positively with desired outcomes of college admission: higher grade point averages and higher likelihood of graduation (in other words, generally speaking, the higher your SAT score, the higher your GPA). For example, writing for Slate, David Z. Hambrick and Christopher Chabris make this very point. This might suggest that the words aren’t irrelevant to test-takers’ chances at success in higher education, and here is where the search for a causal mechanism kicks off. One such causal explanation might go something like this. While the frequency of 50 or so of these 100 words is negligible, they may simply provide a sample we can use to estimate the size of the test-taker’s receptive or productive vocabulary, and vocabulary size may be important for academic success. This explanation then suggests that the SAT mirrors the methods that researchers of vocabulary use to estimate vocabulary size (see this webpage for some of these methods or if you can get access to it, this article).
However, for a test to estimate vocabulary size it would have to depend on a crucial assumption: that the test-taker does not anticipate a test of their vocabulary knowledge and/or has no way of anticipating what words might appear on the test. This is usually the case for vocabulary research, whose participants don’t cram for hours in the off chance that they might get the chance to impress a researcher. However, the assumption is a poor one for the SAT. A simple Google search for “SAT vocabulary” brings up millions of websites purporting to provide assistance in learning words that commonly appear on the test suggesting a vast industry of test preparation emanating from the test and its role in institutional gatekeeping. I have already provided Kaplan’s list of what they claim are the 100 most common SAT words . There are countless more. SparkNotes, for example, purports to be able to provide the 1000 most frequent SAT words. SparkNotes has even produced a series of novels written to make use of 1000 vocabulary words commonly found on the SAT.
The existence of this industry is important because it suggests quite clearly that people are aware that they will be tested on vocabulary and are trying to anticipate what they will have to know to provide a favorable estimate of their vocabulary size. In addition, these preparation strategies also connect back to socioeconomic status. In a paper in the journal Social Forces, Claudia Buchmann, Dennis Condron, and Vincent Roscigno demonstrate how preparation materials for the SAT including courses and private tutoring are more readily available for the students of wealthier families and provide an advantage to these very students. You might think that this isn’t a terrible thing because, (following the ‘predictive validity’ argument) even if students are using test preparation materials, they’re learning words that will help them in their later academic work, but alas I’ve already addressed how this is not really the case. Most of the common SAT words are essentially irrelevant to doing academic work. That means that, in its current form, the SAT vocabulary section tests not academic vocabulary but something more like shibboleths of social class.
Why then would there be a correlation between SAT vocabulary scores and things like grade point average and timely or likely graduation? I believe that this can be explained largely through understanding that the impact of students’ social class does not cease once they enter college. Students of lower classes are, for example, more likely to work full- or part-time while attending college or to transfer between institutions to save money. Thus, the very same advantages that provided access to preparation for the SAT vocabulary test also shields students of higher social classes from the obstacles to academic success that lower class students face.
To wrap this up, there is clearly a connection between, on the one hand, literacy practices and even vocabulary acquisition and, on the other hand, the successful undertaking of academic work. I believe that the modifications to the vocabulary test that the SAT is proposing for its Spring 2016 release better approximate the types of literacy practices that are relevant to success at using academic language. An article at TIME provides an illustration of how rather than being expected to memorize words, test-takers will have to engage in the process of interpreting the meaning of words in context. I believe that this is a more valid approach (in the sense that it better approximates what college students are asked to do), and I hope it provides some small step toward addressing the disadvantages faced by students of lower socioeconomic status.

[…] to word it: social classes can determine your whole life if you let them, your or someone elses social class can stop you from doing something that might otherwise change your life, social classes can shape […]